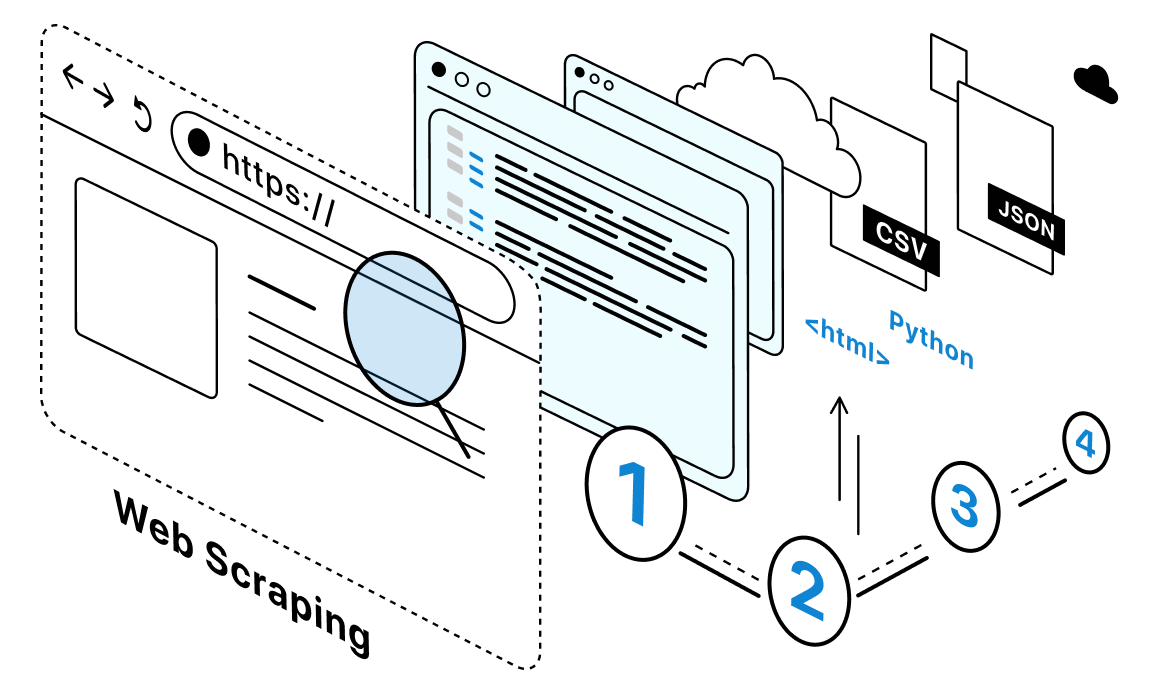
El web scraping es un método de recuperación de datos web a partir de páginas web basado en código. Este método está diseñado para automatizar la transformación sintáctica de páginas web creadas con HTML y XHTML en otras formas, por ejemplo, en tablas con los datos requeridos.
El motor de búsqueda y navegador DuckDuckGo es una de las alternativas gratuitas al monopolio de Google más populares del mercado actual de Internet. El principal factor que impulsa la popularidad de DuckDuckGo son sus funciones de privacidad y seguridad del tráfico. Con DuckDuckGo puedes estar seguro de que no se recopila ninguno de tus datos para modificar los resultados de búsqueda. En esta guía veremos cómo proteger aún más tu privacidad y cómo utilizar proxies con DuckDuckGo.
El scraping de motores de búsqueda extrae automáticamente datos de las páginas de resultados de los motores de búsqueda (SERP). Esto podría abarcar el raspado de resultados orgánicos, anuncios, búsquedas relacionadas y otros datos de motores como Google, Bing, Yandex, etc.
El raspado de motores de búsqueda proporciona inteligencia competitiva mediante el seguimiento de las clasificaciones, los costes de los anuncios, las palabras clave relacionadas y mucho más a lo largo del tiempo sin esfuerzo manual.
Una colección de datos organizada hace referencia a la información estructurada que se almacena y gestiona sistemáticamente para su posterior acceso y uso. A diferencia de los datos dispersos, una colección organizada agrupa componentes de datos relacionados de una manera estandarizada que permite la búsqueda, el análisis y el intercambio eficientes.
No podemos llegar a ninguna parte en el raspado de datos sin un buen localizador. Estas inteligentes herramientas automatizadas se sumergen en las profundidades de un árbol DOM y seleccionan los elementos que necesitamos para nuestros bancos de datos. A menudo surgen dos programas en las conversaciones a la hora de elegir el mejor localizador para el trabajo. Algunos apuestan por un localizador XPath, mientras que otros recomiendan un localizador CSS. ¿Es uno mejor que el otro? Echemos un vistazo a Selector CSS vs XPath para ver cuál es la opción ideal para su proyecto.
Durante bastante tiempo, Twitter, o simplemente X después de que Elon Musk comprara la red social, fue una de las principales plataformas para blogs, noticias, debates sobre tendencias y muchas otras cosas. Recopilar información de Twitter puede aportar muchos datos útiles sobre tendencias actuales, opiniones y temas populares en general. Un análisis de todos estos datos puede servir como motor principal para el SEO y los procedimientos de marketing de la empresa. En los párrafos siguientes, veremos las herramientas para el web scraping de Twitter y veremos cómo pueden ayudarle a realizar el scraping.
Internet alberga vastos océanos de datos, pero para acceder a ellos es necesario descifrar su funcionamiento interno. El web scraping proporciona las claves para desentrañar HTML, CSS y JavaScript, traduciendo el código en bruto en información comprensible.




El web scraping es un método de recuperación de datos web a partir de páginas web basado en código. Este método está diseñado para automatizar la transformación sintáctica de páginas web creadas con HTML y XHTML en otras formas, por ejemplo, en tablas con los datos requeridos.