Claim Discount Coupons in our Community: 200 Points Signup Bonus
Proxy market is always ready to provide a big number of options to choose from. Competition is constantly gaining momentum and not many services remain noticed. 911 proxies offered some unique options that allowed them to take their niche. But this didn't protect them from hacker attacks and shut down later on.
HTTP cookies are short text files that your device saves in its memory when you visit any website. When a file is created by the browser, it stays in the cache. In this cookie file, the browser keeps information about your actions on each site, your login info, browsing history and other preferences.
More and more colleges, schools, and workplaces today ask you to set up proxies to access the internet. That is done to establish better connections or to restrict access to inappropriate information. However, you can also use proxy settings in your everyday net surfing to access geo-restricted information or keep your IP address hidden.
Web scraping has become a vital tool for many businesses nowadays. It allows individuals and companies to collect useful data from websites, process it, and apply it for different goals. Picking the right tools is essential for the effectiveness of that task. Today, Golang and Python language have become some of the best options for web scraping. In this article, we will explore the pros and cons of using Python and Golang language as such tools, comparing their speed, scalability, and suitability in different scenarios.
You may be familiar with the concept of human language grammar, syntax, and interpretation. The same principles apply when we are talking about a computer language with one fundamental difference: here you need to be understood by the machine and its configuration, so that your commands would be “interpreted” properly to get the expected or desired results on the output.
When it comes to buying a rare pair of one of those Adidas or Nike shoes you might have already faced the fact that the top-of-the-line sneakers are hard to buy: producers ship only limited batches that can be sold out within seconds from the renowned online stores.
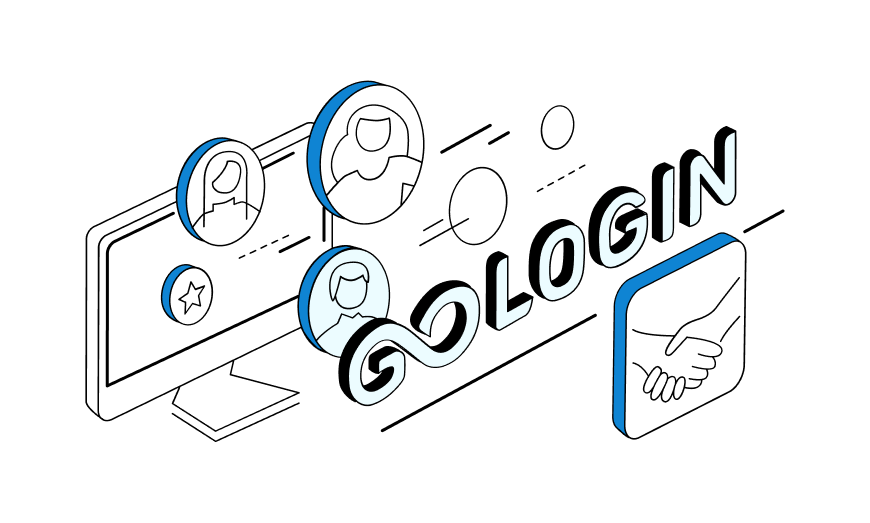
Partnership with GoLogin
We at PrivateProxy are happy to announce our partnership with GoLogin, a service for managing multiple user accounts from a single computer.

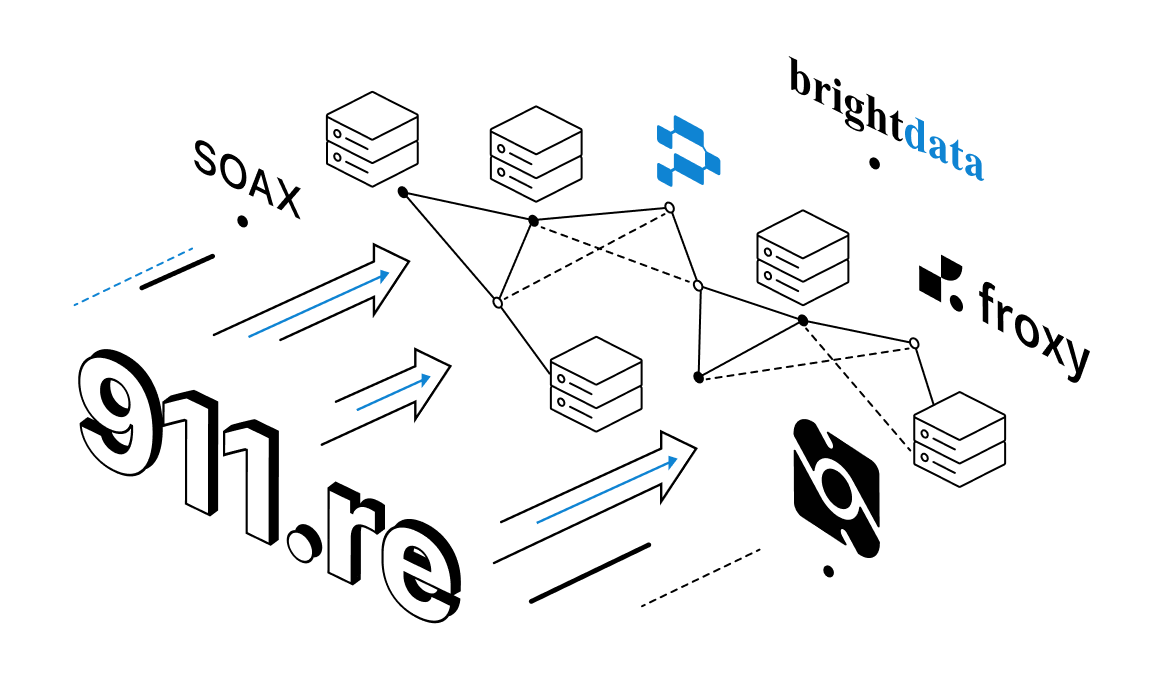





Proxy market is always ready to provide a big number of options to choose from. Competition is constantly gaining momentum and not many services remain noticed. 911 proxies offered some unique options that allowed them to take their niche. But this didn't protect them from hacker attacks and shut down later on.