
ScrapeBox is a must-have tool for all those involved in SEO related activities. It claims to be the “Swiss Army Knife of SEO experts” and deservingly so.
For under $100 you get an app that covers a lot of essential tasks involved in SEO from keyword harvesting and backlink management to automated comment posting in blogs. For the purposes of our ScrapeBox Tutorial, we will concentrate on how to use ScrapeBox and its functionality related to proxy servers. Here you will learn how to use this powerful tool for scraping the web using a set of freshly purchased private proxies provided to you by privateproxy.me.
The Main Features of ScrapeBox and What It is Used For
Let’s start with the basics of the tool to learn how to use ScrapeBox. First, we suggest taking a look at the interface of the platform from the perspective of what ScrapeBox is used for and what areas serve which purpose.
If you are familiar with ScrapeBox you can skip this part and go straight to Proxy Settings.
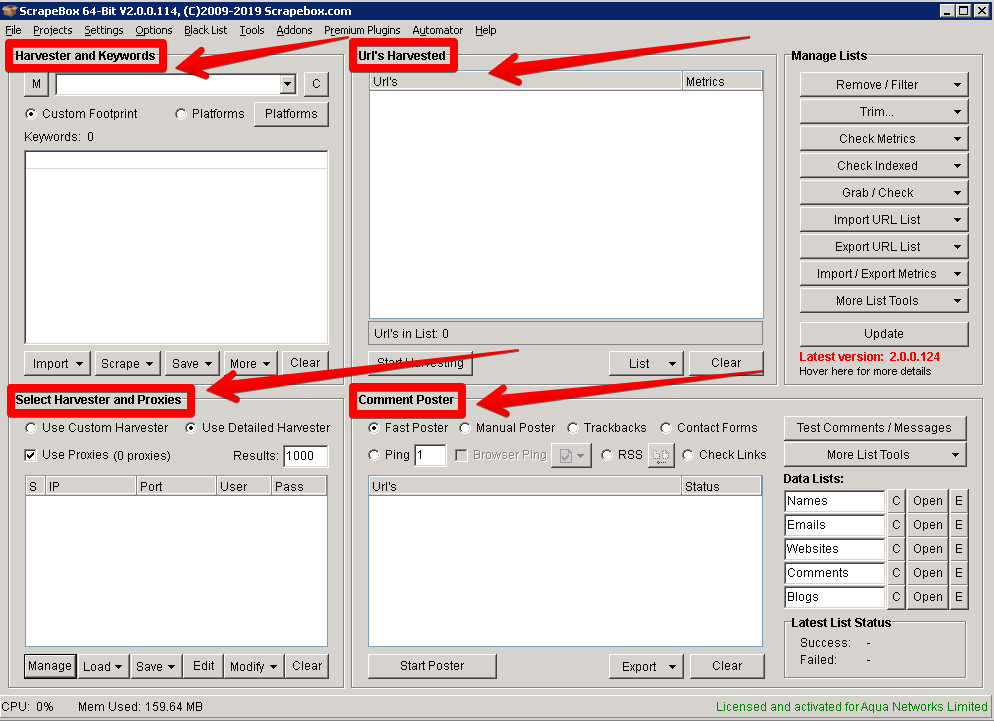
Harvester
Use this block to enter all info related to your harvesting. The top field is used for entering the footprint you need for scraping blogs or other resources. Selecting “Custom Footprint” will let you narrow down your harvesting and improve the results.
URL’s Harvested
This area is used to monitor the results of your harvesting. It will contain the information on the number of harvested URLs and their PR. Later you will be able to use the functionality of controls to the right of this block called “Manage Lists” to perform a range of functions related to filtering, saving, importing and exporting the URL lists.
Select Engines and Proxies
This block is used for two things. First, you can select the search engines to be used during harvesting. Some cases of scraping require adding, say, Yahoo or Bing to the list of engines. And, second, you can enter proxies into ScrapeBox here to make sure that your scraping activities do not get blocked by Google or others. Read on to find out how you can enter your private proxies into the app.
Comment Poster
This block is not recommended for white hat SEO practices, since automatic posting of comments to a mirriads of harvested blogs is not really welcomed. But this function can be really useful for pinging URLs to get them indexed a lot faster.
Why It’s Better to Use Paid Private Proxies: Disadvantages of Free Proxies
Permanent bans
If you are using free private proxies for Scrapebox you have a lot more risks to get banned on various sites than with paid private proxies. For instance, using public proxies for posting on blogs may result in permanent bans on such blogs by anti-spam filters. This happens as a result of these proxies being abused by other proxy users posting on popular blogs and sites’ protecting against that.
Failed Page Rank Checks
Free proxies also very well may fail you during Page Rank checking. Experts say that they tend to return different results each time you run the checks. Where the results of paid private proxies are always consistent and reliable.
Blocks by Google
Free proxies are also vulnerable to getting blocked by Google very quickly. Even if they pass the test initially, within a few hours they might already be dead thus compromising your Scraping results or failing the whole task if you just leave it to do its job without checking regularly. The reason is obvious. All users of Scrapebox (which I would calculate in tens of thousands) have access to the same free lists of proxies and even if the majority of them would use Scrapebox wisely, the chances are high that a couple of newbies would sneak in with some inadequate expectations to hide their activities and Scrapebox settings spoiling it all for everyone else who uses the same free lists.
Even in an ideal world where this does not happen, the sheer number of people using the same proxies on Google at the same time would trigger Google filters and burn the proxies down in a matter of days, if not hours.
ScrapeBox Integration
While there is an option to use free proxies from within ScrapeBox, seasoned SEO specialists understand that such proxies are heavily abused by all those thousands ScrapeBox users and are far from being reliable. In this ScrapeBox tutorial we will show you how to run ScrapeBox on highly effective proxies from a reliable datacenter proxy provider to escape the fate of using public proxies.
In order to enter your private proxies into ScrapeBox proceed as follows:
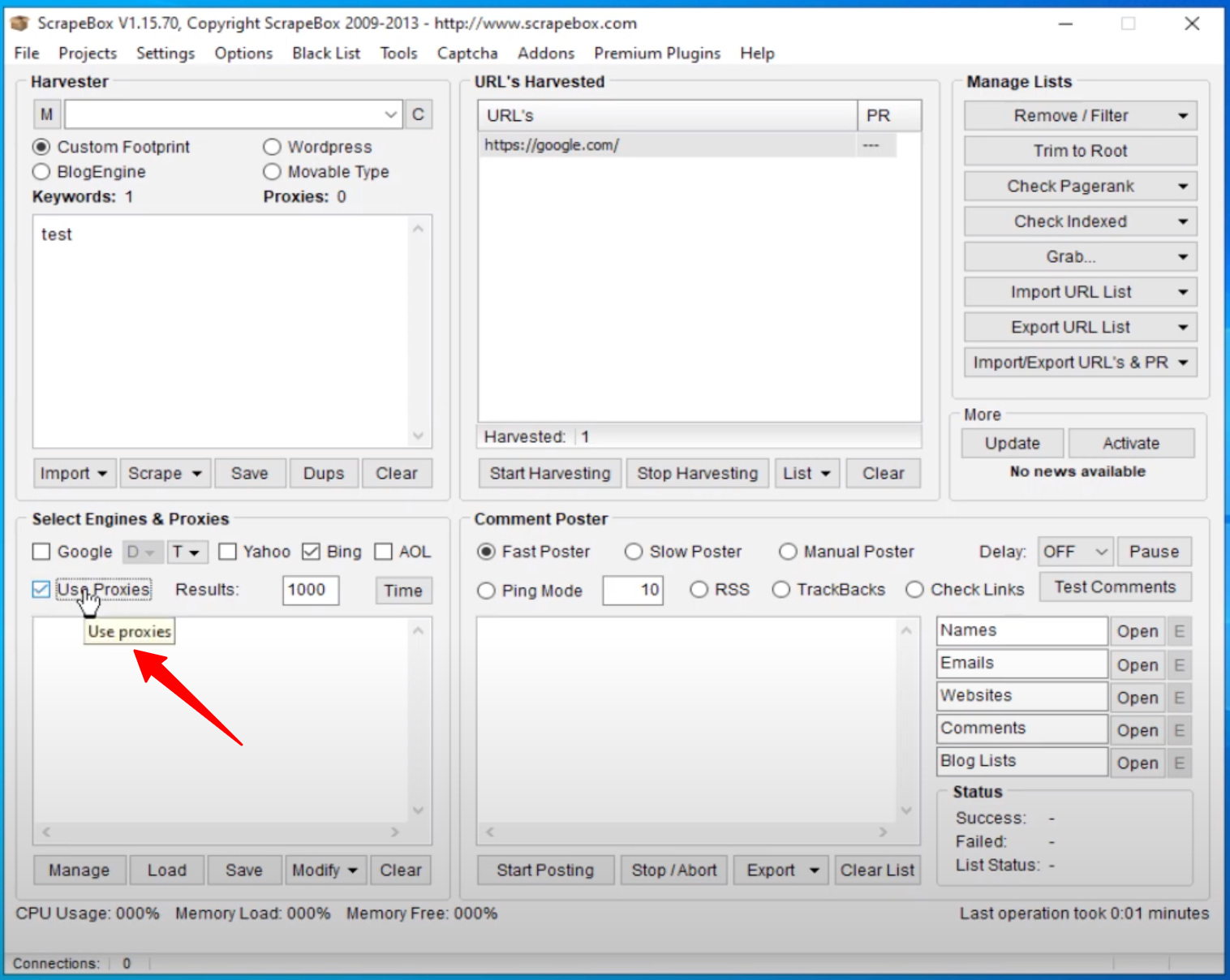
- Click the Use Proxies box to enter your proxy credentials in the field below. For a private proxy you will enter the proxy IP followed by its port, username and password (use this format: ip_address:port:username:password).
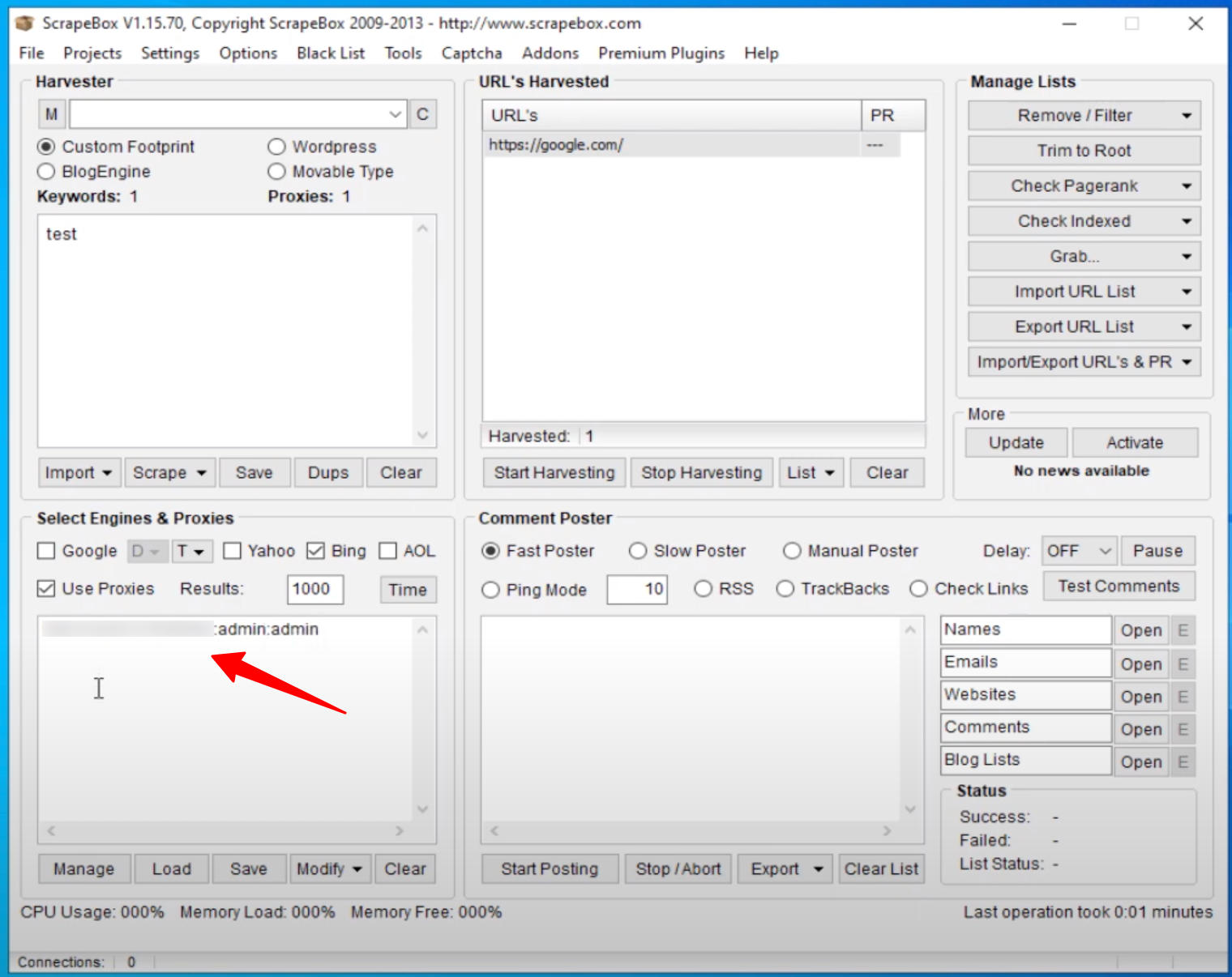
- You can save yourself a lot of time by loading a whole proxy list into ScrapeBox. To do that click Load and select a text file with all your proxies.

- You can also have an option of managing the list of proxies via copy and paste. For this click Manage in the Proxy block below to open up a window for pasting your proxies. Simply copy all proxies from your PrivateProxy.me proxy dashboard and choose Load From Clipboard in ScrapeBox.
- Now, if you want to test your proxies before you initiate your harvesting, you can initiate testing right from the Proxy Manager. For this select Test All Proxies from the menu below.

- If the test is OK, click Start Harvesting to proceed with data harvesting using your newly added and tested proxies.

Testing Rotating Proxies
Once you have your proxies entered into ScrapeBox you will be able to test them before using. All proxies that are OK to go (like google-passed proxies) will be colored green and failed proxies will appear in red. At this stage you can also filter out proxies that will work with Google. This is done to ensure safe scraping once you start it. Testing in ScrapeBox can be also applied for proxies that you want to use for copping sneakers online. Read this article on how to cop sneakers for retail to find out about the best proxies to pick in this case.
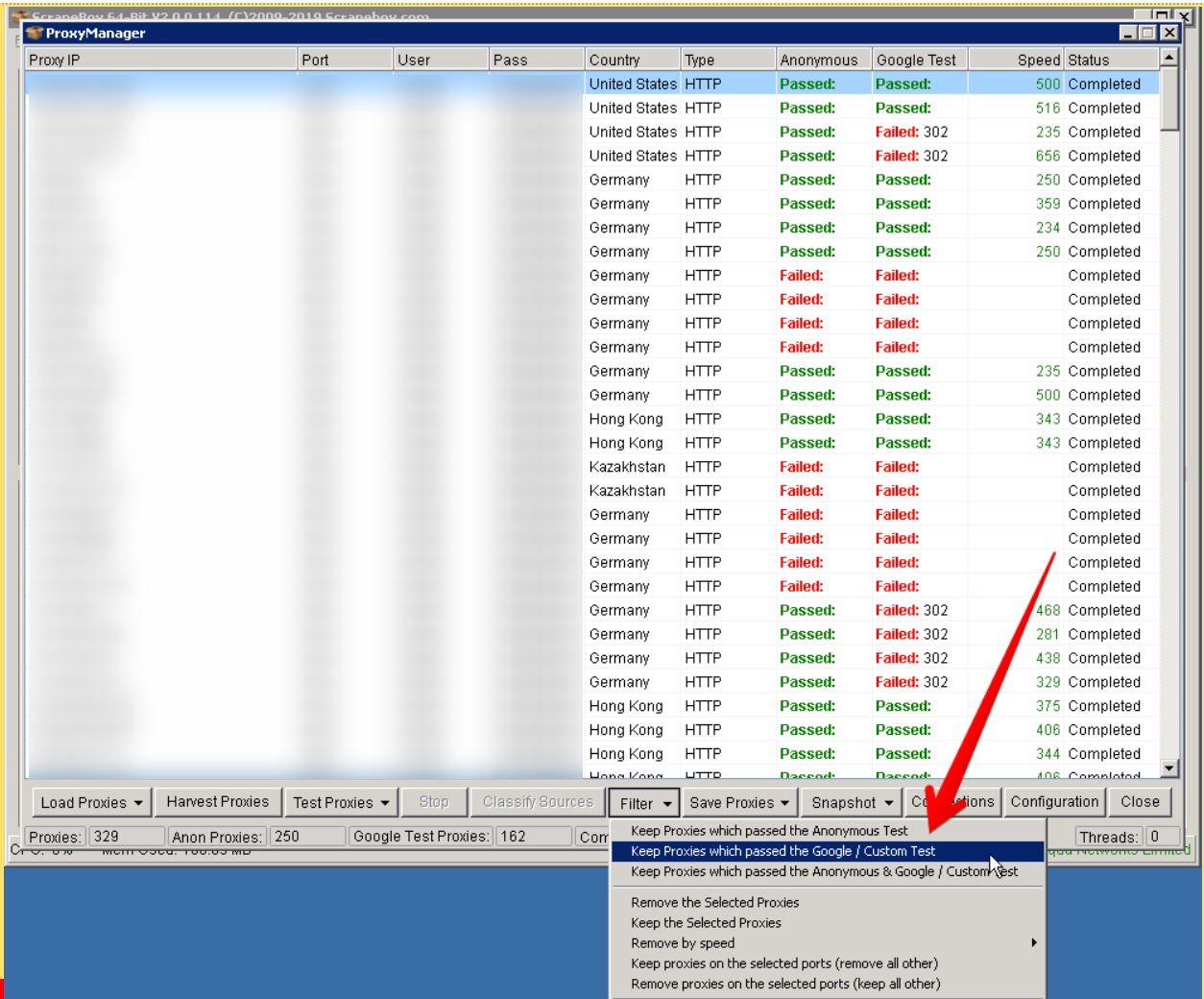
However, there is one important moment about testing proxies. If you are using backconnect rotating proxies there is no need to test them. In other words, if you bought datacenter rotating proxies to be used in Scrapebox, you can go ahead and use them without testing. But if you still decide to run the test and proxies appear to fail the anonymity test, do not worry. The point is when testing for anonymity ScrapeBox compares your proxy IP address to the IP it gets after activating the proxy and in case with backconnect or reverse proxies (that use multiple IPs on the backend) it will not be the same. Although, the same proxies may very well pass the Google test.
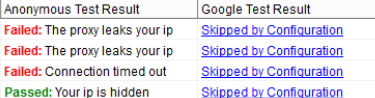
So, we recommend just using such proxies without testing. If such proxies fail to operate, you will know it for having zero scraping results anyway. In this case, you will need to go and check your proxy authorization settings first before raising a question with the proxy provider.
Proxy Settings for Proper Operation of ScrapeBox
Static Proxies
There are some settings that you can adjust to ensure proper operation of ScrapeBox for scraping Google. You need to set the proper ratio of the number of proxies to connections (threads) in ScrapeBox. Google is continuously tightening its grasp on automation tools and proxy usage and as of 2020 for dedicated datacenter proxy this number can be 100 or even more proxies per connection. So, if you have 100 proxies, for instance, you might want to set connections 1 to stay on the safe side. (Contact our account manager to give you the optimum parameters for paid static residential proxies in this application.)
Let’s take for example a situation when you have 100 proxies for scraping. If you want to use the Custom Harvester, you can go to Settings -> Connections, Timeout and Other Settings in the menu. For 100 proxies you should set the Harvester at 1 connection to be safe.

When you run a Detailed Harvester with, say, just 10 proxies, it will obviously put your proxies at risk of getting banned since the 100/1 ratio is not kept. You will, however, have an option to use a Delay in seconds. And you can set a delay of around 10-15 seconds to meet that ratio.
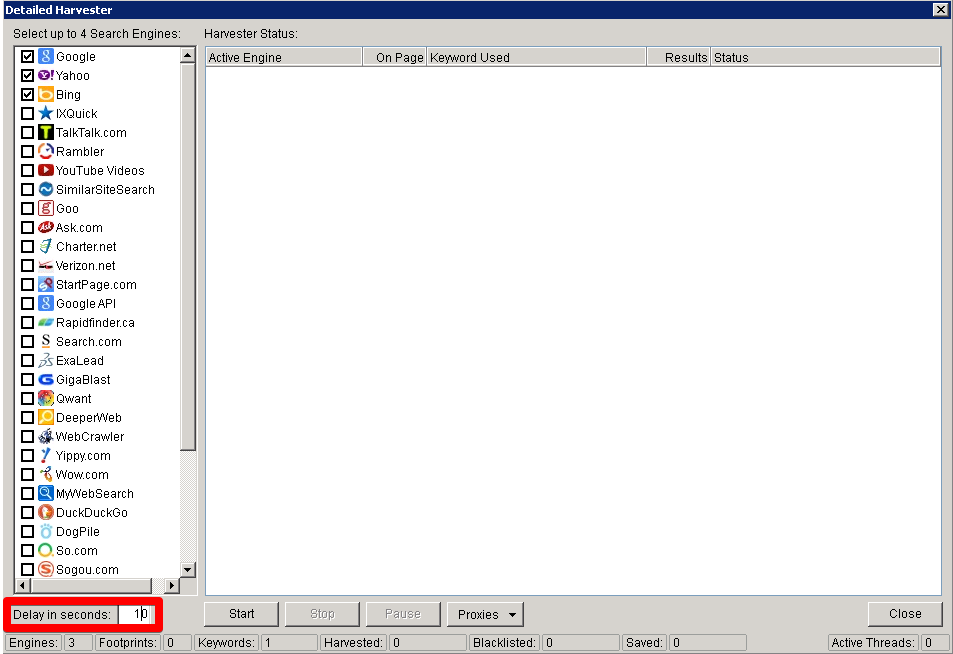
If you use advanced operators Google will be even less tolerable. You should double or triple the delay or the proxy list or both. Again, you need to experiment a bit to optimize your pace of harvesting when you try to scrape Instagram or other sites in this category. In some cases the delay can be up to 300 seconds, depending on the difficulty of your queries but you can set it up once and walk away letting ScrapeBox run for many days.
So, the rule of thumb on connections and delays is like this: depending on your queries, set the number of threads to 1 for every 100 proxies and decrease it if you get many bans. Same for the delays. If you run 30 proxies with 5 seconds delay and get bans – increase the delay to 10 seconds. If everything is going great, you can take it down to 7 seconds for scraping. You can also use headers in web scraping to avoid additional problems in the process.
Rotating Proxies
When you are scraping Google it is also a good idea to use Backconnect proxies (also known as Rotating or Reverse proxies). These proxies change the IPs on the backend from a pool of IPs. This way your personal IP and the IP you are connecting to are completely invisible for Google. It is also very good financially, because you don’t need to buy hundreds of proxies to ensure the same level of anonymity.
When using rotating proxies for scraping, we recommend to limit the number of connections, or threads, to 25% of the threads allowed for your account. The remaining threads can be used for posting from ScrapeBox. As far as the timeouts, you can set it to a figure that can be convenient for you depending on where you are connecting from. Normally, it can be from 30 to 60 seconds.
These two settings: number of connections and timeouts are interrelated. The optimal settings would depend on your PC or server memory, processing capacity, connection bandwidth and many more. Remember, when ScrapeBox is working it emulates a browser and if you set your timeout too low, in some cases a site just won’t have enough time to load and the app will go to the next one.

Also, don’t forget to set the number of retries for each set of keywords before ScrapeBox moves on to the next proxy. This value should be set in the “More Harvester Settings” tab. This is especially essential when using backconnect proxies with instant rotation, since a new IP will be tried on each attempt to connect. In this case also do not forget to uncheck “Remove failed proxies” box, which is typically used for static proxies.
Starting Scraping
Depending on your settings (footings and keywords) scraping can take from several minutes to a whole day. This time can be reduced by allocating more RAM to this function or by using a Virtual Private Server. Before you start your scraping session please decide on the number of proxies and connections you will be using as well as the speed of your proxies. These settings will depend largely on the number of keywords that you will be using during scraping.
After this you can proceed with the footprint and keywords. Let’s say you will be scraping blogs, so we can use “leave a comment” for your footprint.

Now, you can paste the keywords for scraping. In our case “hosting plans” and “web hosting”.
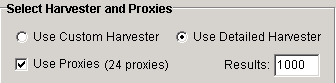
Do not forget to check the “Use Proxies” box for engaging your private proxies.
The field “Results” indicates the number of results you will get per each keyword. If you want to get just a few sites, put another figure (for example, 10). The maximum number of sites is limited to 1000 in ScrapeBox.
Also, to narrow down your search you can add the so-called “stop words”. Such words as “need”, “from”, “make” can significantly improve your results when added to your keywords.
These are just a few recommendations to get you started with ScrapeBox. You will be able to find more information, references and tips on use cases on the official website of the application.
In Conclusion
ScrapeBox is a very powerful SEO tool and can be used for a whole variety of purposes. On the Web (in blogs and forums) you can find a detailed description of how you can use it for page link building without browsing, competitor backlink analysis, finding guest post opportunities, and many more. The purpose of this Guide is to give you some insights on how to properly set up and use proxies with ScrapeBox. We hope that you will find our recommendations useful. If you have further questions, our account managers will be more than happy to assist you in securing the right selection of proxies for your ScrapeBox applications. To contact us, just start a conversation in the box located in the bottom-right corner of your screen. Cheers!
Frequently Asked Questions
Please read our Documentation if you have questions that are not listed below.
-
What is Scrapebox used for?
Scrapebox is often referred to as a “Swiss Army Knife of SEO experts” for being an all-in-one application for various SEO related activities. You can easily use this app for keyword harvesting, backlink management and for automating commenting and posting in blogs. Scrapebox requires proxies for seamless operation during its scraping and harvesting missions. We supply premium private proxies to ensure such operation. If you care to learn more about using our proxies for Scrapebox or you are ready to buy proxies for Scrapebox from Privateproxy, contact us and our account managers will promptly help you with this matter.
-
How to add proxies to Scrapebox?
The process of entering proxies into Scrapebox is as easy as copying your IPs from the dashboard and pasting them into the Scrapebox’s proxy loading menu. Once loaded, you can run a test on proxies to make sure that they are properly tuned for scraping. Note that you do not need to test backconnect rotating proxies though, since the system will generate an error on the anonymity test.
-
What are the best private proxies for Scrapebox?
Although Scrapebox features a range of public proxies to be used with the app, they are far from being the best proxies for Scrapebox and the maximum performance can be only achieved with paid private proxies (SOCKS protocol or HTTP proxies). You can buy static or rotating proxies that will do the business just fine. Make sure you will read the article above on how to properly set up the proxies that you buy inside the Scrapebox. If you have further questions on what proxies to use and how to integrate them with thу application, please consult with our account manager.
Top 5 posts
![What is a SOCKS5 Proxy Server and Why You Should Use It [Complete Guide]](https://privateproxy.me/wp-content/uploads/2021/11/580x348-What-is-a-SOCKS5-Proxy-Server.png)

It is really surprising how many people or even customers of proxy providers don’t even have a clue that they use proxy servers in everyday life while working remotely from their homes, hotels, and remote offices when they access their corporate networks. The whole idea that a computer is assigned an IP (Internet Protocol) number whenever it goes online is mind-boggling for most PC users. But this very phenomenon creates some critical vulnerabilities related to security risks and data privacy.